스타 스키마와 One Big Table 사례 찾아서 공부해보려고 스크랩만 해두고 한참 미뤄뒀었는데 마침 좋은 영상이 유투브 알고리즘으로 찾아왔다.
Data with Zach 라는 처음 보는 채널인데 한때 Airbnb, Facebook에서 일했고 지금은 dataexpert.io 라는 온라인 코스 운영자인 네임드 데이터 엔지니어인 듯하다.
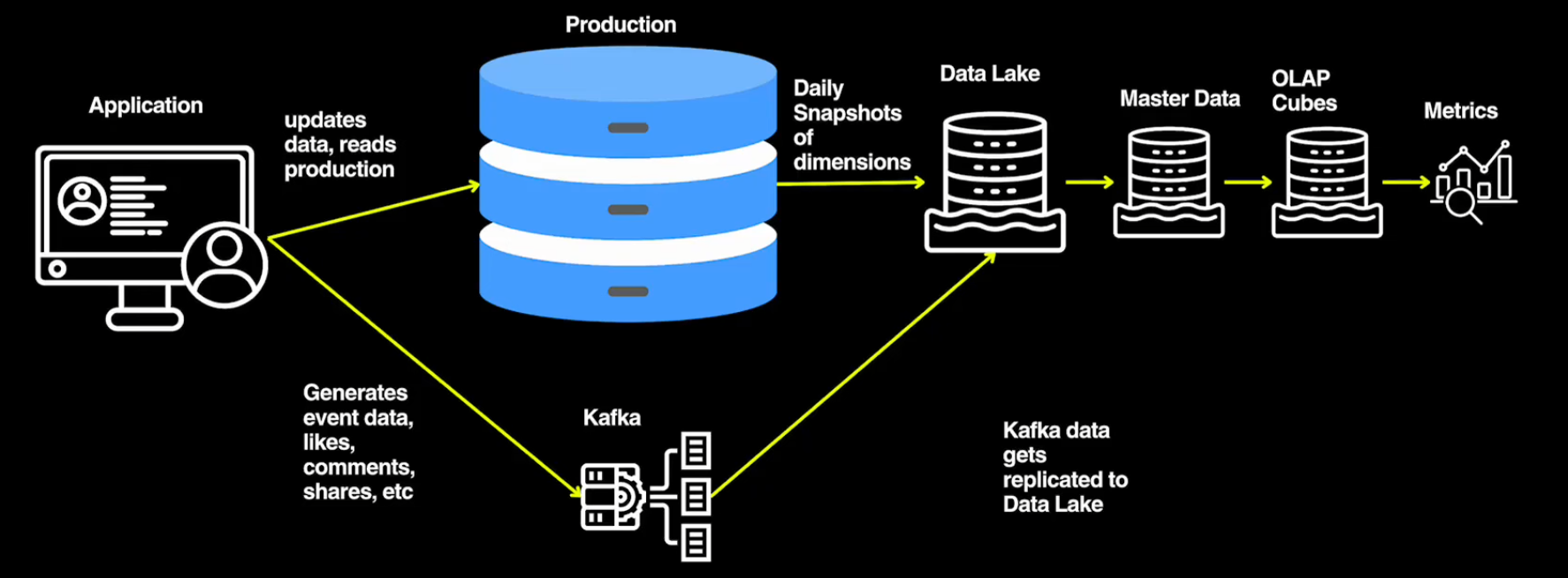
General Enterprise Data System Architecture
아무튼 이 영상에서는 다음과 같은 데이터 레이크 기반 데이터 시스템 아키텍처에서 production -> dimensional -> obt 흐름으로 필요에 따라 추가로 도입해나간다. count the number of deleted posts that contain "SQL sucks" 와 같은 요건을 각 데이터 모델에서 구현해보고 한계점을 마주하면서 그 다음 데이터 모델로 전개해나가는 흐름이어서 각 데이터 모델의 한계와 다른 데이터 모델의 필요성에 대해 쉽게 이해할 수 있었던 것 같다.
Relational Data Modeling
Pros
- Great for single entity access
- Great for adding small amounts of data via transactions
- Minimizes data duplicatoin
Cons
- Analytical questions need many joins to solve
- You only have the latest state of the data
Kimball / Demensional Data Modeling
Pros
- Great for analytical access, especially converting into OLAP
- Great for analysis of large amounts of data and historycal data
Cons
- Transactions should be modeled relationally
- Updating individual records is laughable
One Big Table Data Modeling
Pros
- Can answer questions minimizing JOINs and shuffle
- Great for long-term analysis or replicating common big JOINs
Cons
- Uses complex data types, hard to query
- Replicates and denormalizes data further, more data duplication
OBT를 설명할때는 Cumulative Table Design 이라는 것도 소개해주는데
사실 우리 회사에서는 다차원 모델은 생략(?)하고 프로덕션 모델에서 곧바로 OBT 모델을 이런 형태로 관리하고 있어서 익숙한 방식이었는데 이렇게 불리는 줄은 몰랐다. 일마감 데이터, 증분 방식 정도로 소통했었는데 Cumulative Table Design 이 일반적인 표현인지 좀 더 알아보고 이게 더 맞는 표현이라면 이렇게 쓰도록 해야겠다.


