회사에서 아이스버그를 드디어 도입하게 된다고 해서 찾아보던 중 나름 최신의 리뷰 논문이 있어서 봤는데 내용이 괜찮은 것 같다.
Disruptor in Data Engineering – Comprehensive Review of Apache Iceberg
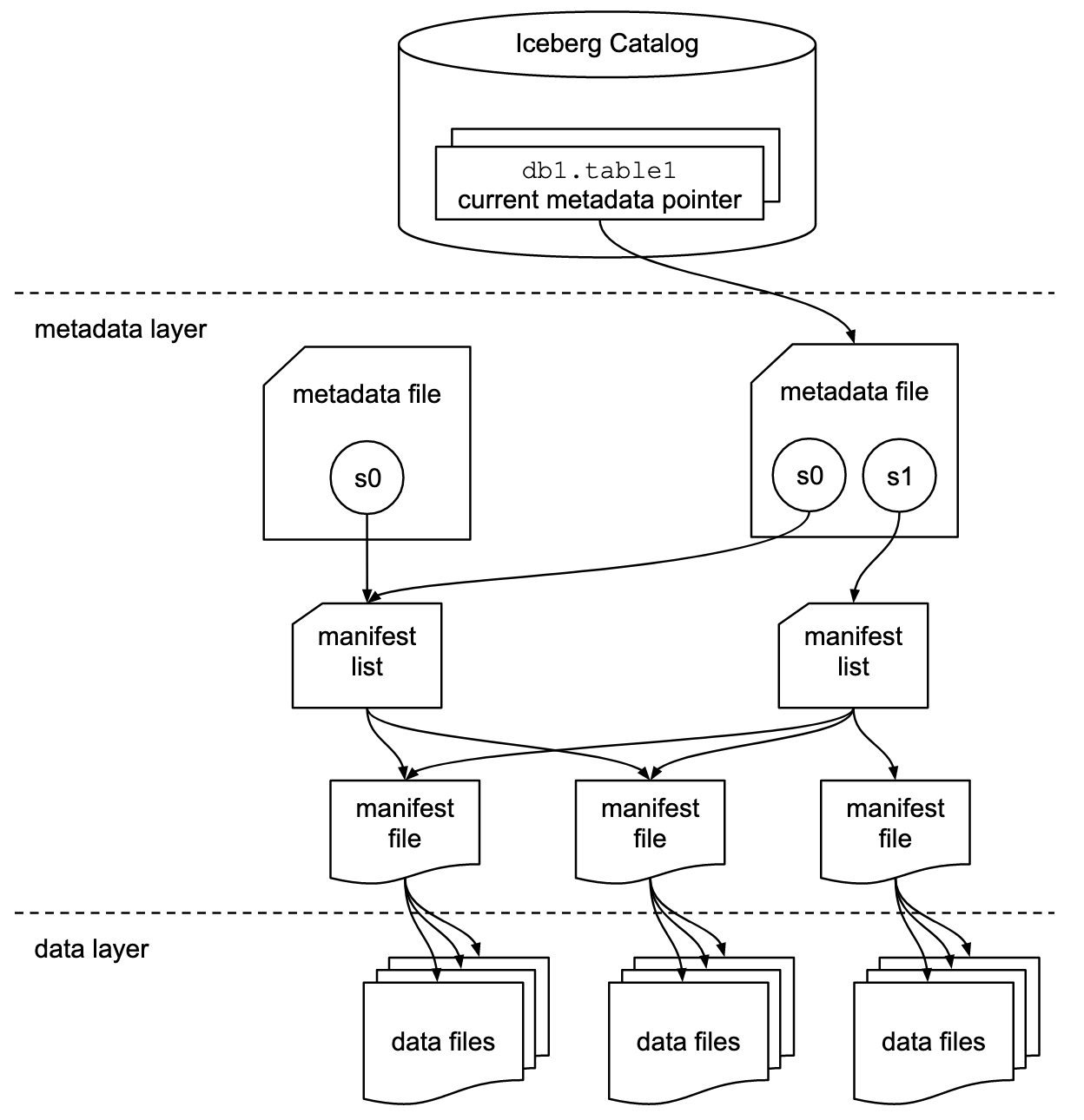
"테이블 포맷"인 아이스버그의 본격 설명에 앞서 Open File Format, Open Table Format, Data Warehouse/Data Lake/Lakehouse 와 같이 배경이 되는 용어들도 한번 짚어주고 시작하는데 Catalog, Metadata, Snapshot 세 계층으로 이뤄진 아키텍처도 잘 정리돼 있고 row-level deletes 가 어떻게 동작하는지 원리도 충분히 설명을 해주고 있다.
대체재 테이블 포맷인 hudi, deltalake 와의 비교 자료도 있고 지원 기능이랑 장점, 한계점 등등 정리가 잘 돼 있다.
5.3 Capabilities
Iceberg as a table format provides several capabilities that’s causing increased adoption of this
technology at a rapid pace in the industry:
- ACID compliance
- data manipulations are atomic providing transaction capability
- Hidden partitioning
- Hive requires manual partition column definitions which is inefficient and complex. Iceberg addresses this limitation by providing a hidden partitioning concept. Iceberg manages partitioning internally by using data structure and metadata and users remain completely unaware of the partitioning scheme [24].
- Partition Evolution
- if performance degrades over time, Iceberg changes the partitioning scheme on its own enabling partition evolution.
- Schema evolution
- Schema evolution is straightforward in Iceberg as only metadata fields are updated. Standard operations such adding a column, dropping an existing column or renaming it are all possible in Iceberg using metadata file manipulation. The data files remain unchanged [26].
- Time Travel
- Change in Iceberg causes creating a new version of metadata called snapshot. Old snapshot remains in the system for a while. This allows users to time travel over data using date range or version number of a snapshot [27].
- Concurrency
- Iceberg allows concurrent reads and writes by multiple engines at the same time leveraging optimistic concurrency control[10, 28]. When there are multiple concurrent requests, Iceberg checks for conflicts at the file level, allowing multiple updates in a partition as long as there are no conflicts.
- File filtering
- The metadata files contain min, max values for a column.This allows query that searches over petabytes of data, come back with result in single digit seconds producing significant fast performance.
- Table Migration
- Iceberg provides a mechanism to create Iceberg metadata files using metadata files of other table formats such as Delta Lake using its table migration feature. It comes in 2 flavors- full data migration and in-place data migration. The full data migration creates a copy of the data files along with creating the Iceberg metadata files. The in-place migration on the other hand reuses the data files and only creates new Iceberg metadata files [29].
6.3 Architecture & Capability Comparison
| Iceberg | Deta Lake | Hudi |
|---|---|---|
| Supports Parquet, ORC and Avro data file format | Supports only Parquet format | Supports Parquet, ORC and Avro format |
| Metadata implementation hierarchical in nature catalog, metadata layer(metadata file, manifest-listandmanifest file) | Metadata implementation tabular in nature transaction log file and checkpoint file | Metadata implementation tabular in nature- partition metadata and timeline metadata |
| No caching support for performance optimization | Delta Cache support for performance optimization | No caching support for performance optimization |
| Supports Copy-On-Write(COW) and Merge-On-Read(MOR) for write operations | Supports only Copy-On-Write(COW) | Supports both Copy-On-Write(COW) and Merge-On-Read(MOR) |
| Hidden partitioning and partition evolution supported | Explicit partitioning required, partition pruning supported | Explicit partitioning required and partition evolution supported |
| Snapshot versions are used for timetravel | Transaction log based versioning for timetravel | Timetravel based on incremental commits and versions |
| Schemaevolution supported including addition and rename of fields | Supports schema evolution without requiring schema migration | Schema evolution supported with automatic handling of schema migration |
| Concurrency writes are supported using Optimistic Concurrency Control and snapshots | Transaction log based Optimistic Concurrency Control | Optimistic concurrency control using multi-version concurrency control |
Iceberg Table Spec
보다 정확하고 자세한 정보는 공식 문서를 참고해야한다.
quickstart
맛보기로 공식 문서에서 제공하는 퀵스타트 가이드를 따라 spark-sql 도 이용해봤는데
https://iceberg.apache.org/spark-quickstart/
제공되는 도커 명세를 그대로 따라서
services:
spark-iceberg:
image: tabulario/spark-iceberg
container_name: spark-iceberg
build: spark/
networks:
iceberg_net:
depends_on:
- rest
- minio
volumes:
- ./warehouse:/home/iceberg/warehouse
- ./notebooks:/home/iceberg/notebooks/notebooks
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
ports:
- 8888:8888
- 8080:8080
- 10000:10000
- 10001:10001
rest:
image: apache/iceberg-rest-fixture
container_name: iceberg-rest
networks:
iceberg_net:
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://warehouse/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- warehouse.minio
ports:
- 9001:9001
- 9000:9000
command: ["server", "/data", "--console-address", ":9001"]
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
iceberg_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: |
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/warehouse;
/usr/bin/mc mb minio/warehouse;
/usr/bin/mc policy set public minio/warehouse;
tail -f /dev/null
"
networks:
iceberg_net:서비스를 구성하고
docker compose up -d
docker exec -it spark-iceberg spark-sql다음과 같이 DELETE operation 을 추가해 쿼리해봤는데 잘 동작한다.
CREATE TABLE
demo.nyc.taxis
( vendor_id BIGINT
, trip_id BIGINT
, trip_distance FLOAT
, fare_amount DOUBLE
, store_and_fwd_flag STRING
) PARTITIONED BY (vendor_id);
INSERT
INTO demo.nyc.taxis
VALUES
( 1, 1000371, 1.8, 15.32, 'N' ),
( 2, 1000372, 2.5, 22.15, 'N' ),
( 2, 1000373, 0.9, 9.01 , 'N' ),
( 1, 1000374, 8.4, 42.13, 'Y' );
SELECT *
FROM demo.nyc.taxis;
-- 1 1000371 1.8 15.32 N
-- 1 1000374 8.4 42.13 Y
-- 2 1000372 2.5 22.15 N
-- 2 1000373 0.9 9.01 N
DELETE
FROM demo.nyc.taxis
WHERE store_and_fwd_flag = 'N';
SELECT *
FROM demo.nyc.taxis;
-- 1 1000374 8.4 42.13 Y퀵스타트 도커 명세에 포함된 mc 를 활용해 SQL operation 사이사이 warehouse 상태를 점검해봤는데 마지막 상태는 다음과 같다.
# tree taxis
taxis
├── data
│ ├── vendor_id=1
│ │ ├── 00000-4-2732d28f-f6ec-4654-9bdc-736051cc9b7e-0-00001.parquet
│ │ └── 00000-9-7e70c547-66cd-41d4-9403-d5aac793cf38-0-00001.parquet
│ └── vendor_id=2
│ └── 00000-4-2732d28f-f6ec-4654-9bdc-736051cc9b7e-0-00002.parquet
└── metadata
├── 00000-22489044-d255-4126-b1c1-be202143039c.metadata.json
├── 00001-47cba4e3-2a1f-4cb4-85ef-ea023c692eae.metadata.json
├── 00002-34f71565-4d72-479e-966a-a449d0a93f91.metadata.json
├── 4d1505dc-d959-4426-a205-b563e48f4268-m0.avro
├── 5c72ac74-0755-4fc1-b368-b55b0e363f43-m0.avro
├── 5c72ac74-0755-4fc1-b368-b55b0e363f43-m1.avro
├── snap-10300693507100651-1-5c72ac74-0755-4fc1-b368-b55b0e363f43.avro
└── snap-2391828917792661493-1-4d1505dc-d959-4426-a205-b563e48f4268.avro데이터 건수가 적어서 그런것인지 spark-sql 을 통해서 그런 것인지는 잘 모르겠지만 DELETE sql 이 최종 스냅샷에서는 overwrite 로 처리돼있다.
{
...
"snapshots" : [ {
"sequence-number" : 1,
"snapshot-id" : 2391828917792661493,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1736957601732",
"added-data-files" : "2",
"added-records" : "4",
"added-files-size" : "3074",
"changed-partition-count" : "2",
"total-records" : "4",
"total-files-size" : "3074",
"total-data-files" : "2",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "s3://warehouse/nyc/taxis/metadata/snap-2391828917792661493-1-4d1505dc-d959-4426-a205-b563e48f4268.avro",
"schema-id" : 0
}, {
"sequence-number" : 2,
"snapshot-id" : 10300693507100651,
"parent-snapshot-id" : 2391828917792661493,
"summary" : {
"operation" : "overwrite",
"spark.app.id" : "local-1736957601732",
"added-data-files" : "1",
"deleted-data-files" : "2",
"added-records" : "1",
"deleted-records" : "4",
"added-files-size" : "1494",
"removed-files-size" : "3074",
"changed-partition-count" : "2",
"total-records" : "1",
"total-files-size" : "1494",
"total-data-files" : "1",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "s3://warehouse/nyc/taxis/metadata/snap-10300693507100651-1-5c72ac74-0755-4fc1-b368-b55b0e363f43.avro",
"schema-id" : 0
} ],
...
}delete-files 로 일부 데이터가 삭제된 척하는 시점을 관측하고 싶은데 조금 더 조사해봐야할 것 같다.


