Apache Kafka
Introduction
이번에 직접 사용해보니..
Message Queue Open Source Framework로서 kafka를 많이들 사용하는 것 같다.
기본적으로 Producer/Consumer Application 을 개발해서 사용해야 하는데 많이 사용하다 보니 관련 자료가 많고 Hadoop, Spark, 여러 수집기 등에서 Plugin을 제공한다.
많이 쓰고 자료가 많아서 kafka를 이용하는 것도 좋은 이유인 것 같다.
다음 두가지 이유가 직접 느낀 좋은 점
- Consumer는 필요한 메시지를 PULL 하는 구조
- 무중단 서비스 구현 가능
Consumer는 필요한 메시지를 PULL 하는 구조
Producer는 Message를 Kafka Topic에 PUSH 하고,
Consumer는 Message를 Kafka Topic에서 PULL 하는 구조이다.
이 때문에 Consumer Application 이 필요로 할 때에 필요한 만큼의 데이터를 가져다가 쓸 수 있다.
무중단 서비스 구현 가능
Fluentd,Logstash 등에서도 Persistent Queue 기능을 가지고는 있지만, member node가 다운되었을 때에 해당 노드에서 잠시라도 버퍼링 한 데이터는 그 노드가 살아나야만 다시 전송할 수 있다.
수집기만 사용했을 때에는 데이터가 유실되지는 않지만 스트림 데이터의 흐름이 깨짐으로써 서비스 중단이 있다.
@Kakao
카카오에서는 아래와 같이 많은 메시지를 카프카를 경유시켜 서비스에 활용하고 있다고 한다.

- 7 Cluster / 130 Node
전사적으로 다양한 서비스에 활용 - 260,000,000,000 (messages / day)
- in: 240 TB/day
- out: 370 TB/day
- 99.99% 가동률
Core APIs
Kafka has four core APIs
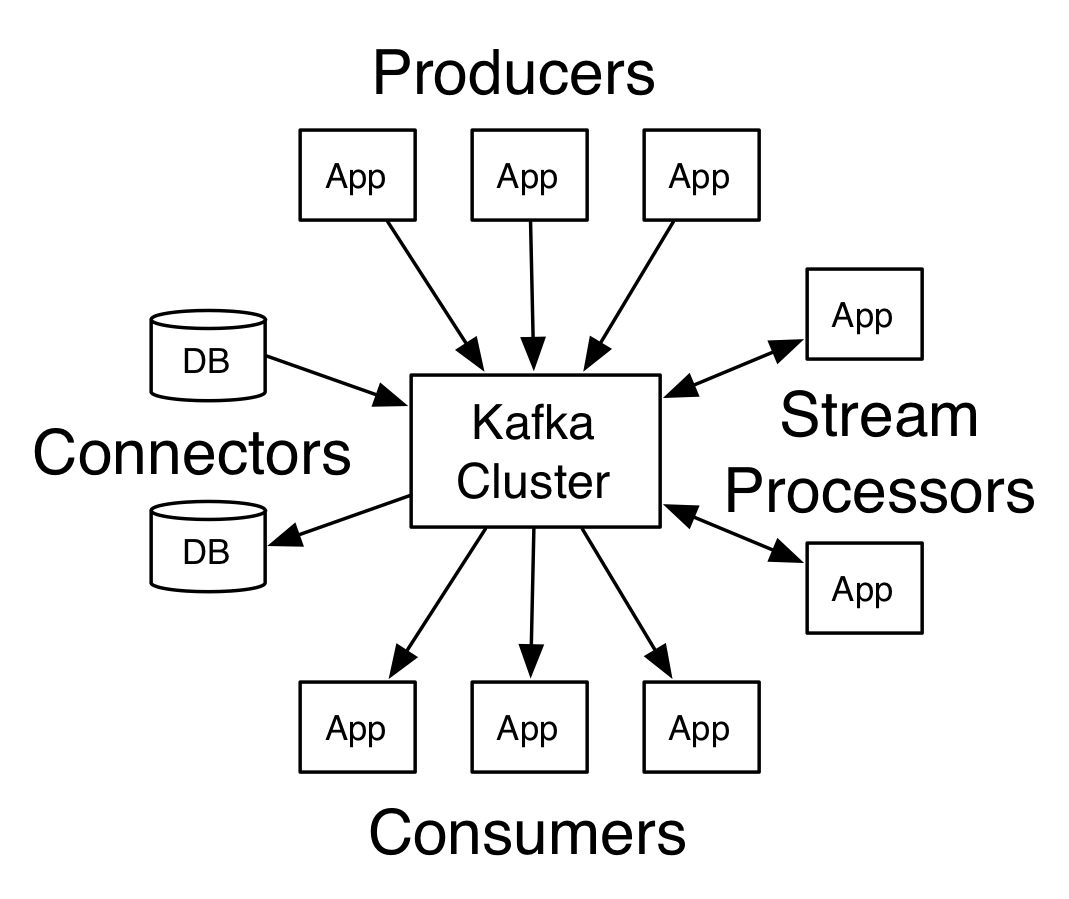
0.10.0 버전부터 Stream API, Connector API가 추가되었다. Producer,Consumer API 가 핵심 구조이며, Producer/Consumer API를 활용해 Producer/Consumer Application 을 개발하는 것이 기본.
대부분의 수집기에서 kafka in/out plugin 을 제공하기 때문에 간편하게 사용하기 위해서는 이들을 이용하면 편하다.
Kafka Cluster 는 수동적이다. 어떻게 보면 DBMS와 비슷한데
데이터를 주면 받고 가져가겠다고 하면 내어준다.
- Producer 어플리케이션은 스트림 데이터를 ‘push’ 하는 형태로 동작.
- Consumer 어플리케이션은 kafka topic에 저장된 데이터를 consumer가 원하는 주기/offset 등을 설정하여 가져가는(PULL) 형태로 동작.
Producer API
kafka topic에 스트림 데이터를 publish하는 API.
- 특정 Topic 의 Leader에게 메시지 전송 (PUSH)
- ACKS
- 0
보내기만 함 - 1 (default, freq)
파티션의 리더가 데이터를 수신했는지만 확인 - ALL
모든 replication이 데이터를 수신했는지 확인
- 특정 파티션 또는 랜덤 파티션으로 전송
- 빠른 전송 속도 보장
- 효율성이 좋은 배치 처리 가능
- 설정을 통해 배치 크기나 지연시간 조정
Consumer API
kafka topic을 subscribe하는 API.
- 특정 Topic 의 Leader에게
Fetch해달라고 요청 (PULL) - 해당 topic의 특정 offset부터 요청
어디서부터 구독할 것인지는 Consumer Application 에서 결정하는데, 과거의 offset으로 reset 시켜서 다시 가져올 지, 최근의 데이터부터만 가져올 것인지를 정할 수 있다.
~~spark streaming의 KafkaUtils에서 offset 을 컨트롤 하는 방법 알아봐야겠다. consumer가 죽엇을 때에 다시 app을 살리더라도 그때 기준 최신 자료부터 가져올 듯.~~
~~죽은 시점의 데이터부터 다시 처리 하는 방법을 알아내야 할 듯.~~
Consumer Group

- 하나의 토픽을 group 내 여러 Consumer 들이 나누어 구독
Producer가 Topic으로 보내는 속도가 빠른 경우 Consumer 확장 가능 - 하나의 파티션에는 하나의 컨슈머만 가능
동일한 데이터를 컨슈머 그룹이 중복해서 구독하지 않는다.
Stream API
kafka 클러스터 자체적으로 stream 데이터 처리 프로세스를 갖는다. 아래와 같은 장점이 있다고들 한다.
- Very light weight library, good for microservices, IOT applications
- Exactly Once
- Does not need dedicated cluster
- Inherits all Kafka Good characteristics
- Supports Stream joins, internally uses rocksDB for maintaining state.
-
tightly coupled with Kafka, can not use without Kafka in picture
- Quite new in infancy state, yet to be tested in big companies
- Not for heavy lifting work like Spark Streaming, Flink
https://www.linkedin.com/pulse/spark-streaming-vs-flink-storm-kafka-streams-samza-choose-prakash
https://www.confluent.io/blog/introducing-kafka-streams-stream-processing-made-simple/
The Connector API
Connector API를 이용하면 Producer Application 과 같이 외부 요소를 사용하지 않고 데이터를 가져오고, Consumer Apllication 과 같이 PULL 요청에 데이터를 주는 것이 아니라 주기적으로 PUSH 하는 구조도 가능한 것 같다.
- Simplifies data flow in to and out of Kafka
- Reduces development costs compared to custom connectors
- Integrated schema management
- Task partitioning and rebalancing
- offset management
- fault tolerance
- Delivery semantics, Operations, And Monitoring
https://www.confluent.io/product/connectors/
https://www.slideshare.net/KaufmanNg/data-pipelines-with-kafka-connect
Topics and Logs
Topic
카프카에 보관되는 메시지를 분류하는 기준
Producer와 Consumer를 연계하는 Channel
topic은 스트림 데이터를 분류하는 category 또는 feed name이다. 하나 이상의 consumer 또는 consumer group 을 가질 수 있고, consumer group 별로 별도의 offset을 관리하므로 consumer group이 여럿이더라도 모두 같은 데이터를 볼 수 있다.
5000개 이상의 topic 을 하나의 클러스터에서 처리하고 있다.
https://stackoverflow.com/questions/32950503/can-i-have-100s-of-thousands-of-topics-in-a-kafka-cluser
how many topics can kafka support?
- it depends:
- num of dirs allowed in FS
- open file handlers (kafka keep all log segments open in the broker)
- ZK nodes
Partitioning
kafka 클러스터는 아래와 같이 하나의 토픽에 대해 파티셔닝을 할 수 있는데,
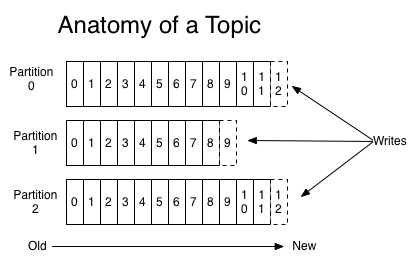
Producer가 메시지를 실제로 어떤 partition으로 전송할지는 사용자가 구현한 partition 분배 알고리즘에 의해 결정된다. 예를 들어 라운드-로빈 방식의 partition 분배 알고리즘을 구현하여 각 partition에 메시지를 균등하게 분배하도록 하거나, 메시지의 키를 활용하여 알파벳 A로 시작하는 키를 가진 메시지는 P0에만 전송하고, B로 시작하는 키를 가진 메시지는 P1에만 전송하는 형태의 구성도 가능하다.
- 파티션 방식
- RDBMS의 Partition 처럼 Key를 통해 분리
- Event 발생 시점 기준으로 Round-robin
- modulo 연산
좀 더 복잡한 예로써 사용자 ID의 CRC32값을 partition의 수로 modulo 연산을 수행하여(CRC32(ID) % partition의 수) 동일한 ID에 대한 메시지는 동일한 partition에 할당되도록 구성할 수도 있다고 한다.
그런데 카카오 Dev에서 Partition 나누면 순서 보장이 안될수도 있다고 하던데 굳이 파티셔닝을 하는 이유는?
각 파티션의 리더가 여러 브로커에 나누어져 분포하도록 알고리즘이 돼 있어 I/O분산이 된다. Consumer Group 을 활용하는 경우 멤버들이 파티션을 나누어 가져갈 수 있기 때문에 의미가 더 생기는 것 같다.
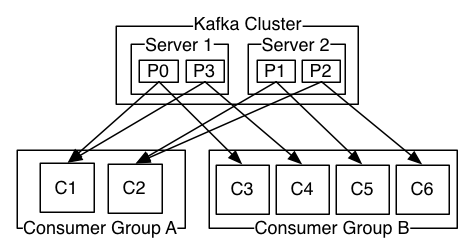
위와 같이 Consumer Group A,B 가 있을 때 A,B 는 각자 offset을 관리하여 topic을 구독한다. 그런데 Consuer Group A 내에서는 Consumer C1,C2 가 P0,P1,P2,P3 를 나누어서 부분적으로 구독한다.

이 때에 각 파티션별 leader P0,P1,P2,P3 는 여러 브로커 서버에 분산되어 있는데 이 때문에 I/O 가 분산되어 효율적이다.
Reliability
ZooKeeper를 이용한 Clustering
단순 수집기만 사용했을 때의 문제를 해결해 줌. 서비스 중단이 없다.

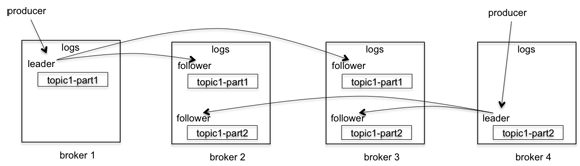
ISR
In-Sync Replication (ISR) 모델 이용
파티션 단위로 replication이 생성되는데 이 분산된 replication과 primary 데이터(leader와 모든 followers)를 그룹으로 묶음.
follower 들은 leader 에게 갱신된 데이터가 있냐 지속적으로 요청하여 갱신된 것이 있으면 데이터를 받아가는 (Pulling) 방식로 데이터를 복제하는데, 여기서 갱신 데이터 요청을 일정 시간동안 하지 않는 follower가 있으면 이 follower를 ISR에서 제외시킨다. 또한 해당 follower가 기록 했었던 offset을 High watermark 처리 하여 디스크에 써둚으로써 이후 장애가 났던 follower가 살아나면 hw 마크부터 데이터를 가져갈 수 있도록할 수 있다.
https://engineering.linkedin.com/kafka/intra-cluster-replication-apache-kafka