requests를 이용한 crawler – 로또 회차별 당첨 결과
Python 을 이용해서 로또 당첨 결과를 수집하는 Crawler를 만든다.
목표
https://www.dhlottery.co.kr/gameResult.do?method=byWin&drwNo=1 페이지에 들어가면 아래와 같이 회차별 당첨 정보를 조회할 수 있는데, 각 회차별 페이지에서 아래 표시된 당첨 번호, 보너스 번호, 등위별 당첨금액, 등위별 당첨 게임 수 데이터를 수집한다.

만들기
requests
pip install requests 명령으로 requests 패키지를 설치한다.
아래와 같이 특정 url에 get 요청을 보내고 text 속성을 조회하면
import requests
url = 'https://www.dhlottery.co.kr/gameResult.do?method=byWin&drwNo=1'
html = requests.get(url).text
print(html)
다음과 같이 html 문서가 전부 반환되는 것을 확인할 수 있다.
[python@node2 crawl]$ python test.py | more
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="EUC-KR">
<meta id="utitle" name="title" content="동행복권">
<meta id="desc" name="description" content="동행복권 1회 당첨번호 10,23,29,33,37,40+16. 1등 총 0명, 1인당 당첨금액 0원.">
<title>로또6/45 - 회차별 당첨번호</title>
<title>동행복권</title>
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<link rel="shortcut icon" href="/images/common/favicon.ico" type="image/x-icon">
<link rel="icon" href="/images/common/favicon.ico" type="image/x-icon">
<script type="text/javascript" src="/js/jquery-1.9.1.min.js"></script>
<script type="text/javascript" src="/js/common.js" charset="utf-8"></script>
<script type="text/javascript">
fn_g_init_message("");
var gameUserId = "";
function goGame(){
var userId = "";
if(userId == '' || userId == null){
alert("로그인 후 사용 해주시기 바랍니다.");
location.href = "/user.do?method=login";
return;
}
$.ajax({
type:"get", // 메소드타입
url:"https://el.dhlottery.co.kr/portal_login.jsp", // url
dataType:"jsonp", //이부분이 중요 데이타타입을 jsonP로 해줘야 크로스도메인을 이용할수 있다.
jsonp : 'callback', // 콜백함수 이름 명이다.
timeout:3000,
error: function() { // 에러날경우 콜백함수
alert('접속이 원할하지 않습니다.');
},
success: function(data){ // 성공했을때 콜백함수
if(userId == data.userId && data.userId != ""){
doGamePopUp("");
}else{
alert("로그인 세션이 해제 되었습니다.\n다시 한번 로그인해 주시기 바랍니다.");
...
..
.
bs4
pip install bs4 명령으로 BeautifulSoup 패키지를 설치한다. BeautifulSoup의 html.parser를 이용하면 html string source를 파싱하고 필요한 요소만 선택하여 활용할 수 있다.
회차별 당첨번호 페이지에서 보너스 번호의 값을 추출하고자 하는 경우 다음과 같은 절차를 수행한다.
1. 페이지 요소 검사
원하는 오브젝트에 마우스를 위치시키고 검사를 수행한다.
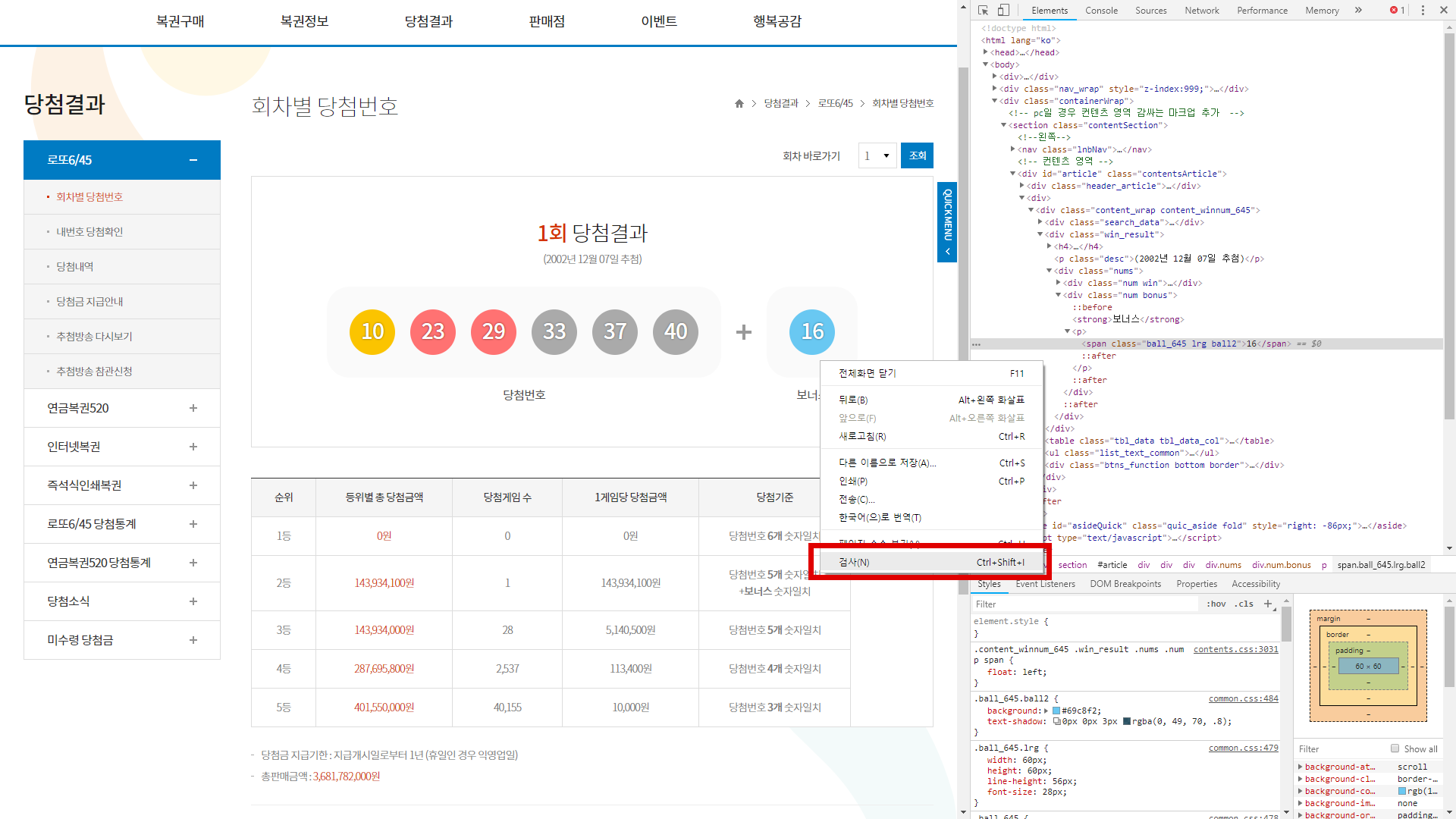
위와 같이 크롬 개발자 도구와 함께 해당 오브젝트의 소스 위치가 하이라이트 된다.
2. selector 복사
하이라이트 된 오브젝트 소스를 다시 우클릭해 Copy > Copy selector 명령을 수행한다.
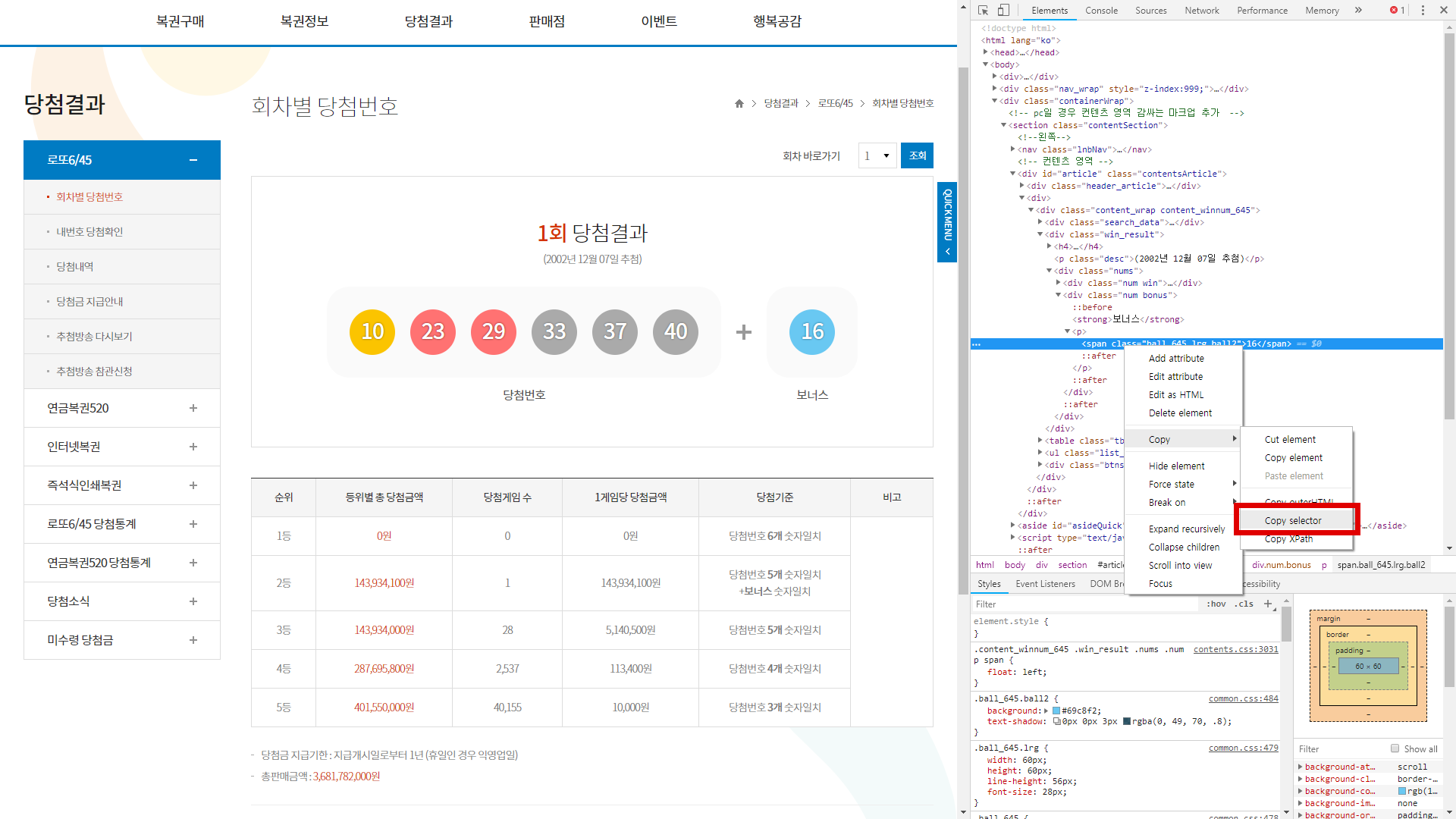
텍스트 에디터에 붙여넣기를 해보면 #article > div:nth-child(2) > div > div.win_result > div > div.num.bonus > p > span 와 같이 selector가 클립보드에 복사돼 있는 것을 확인할 수 있다.
3. 보너스 번호 추출
앞서 사용한 requests 코드에 이이서 다음과 같은 프로그램으로 보너스 번호를 추출할 수 있다. 복사한 selector 에서 nth-child(n)는 nth-of-type(n) 으로 변형하여 사용한다.
import requests
url = 'https://www.dhlottery.co.kr/gameResult.do?method=byWin&drwNo=1'
html = requests.get(url).text
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'html.parser')
selector = '#article > div:nth-of-type(2) > div > div.win_result > div > div.num.bonus > p > span'
print(soup.select(selector))
bonus = int(soup.select(selector)[0].text.strip())
print(bonus)
프로그램 출력을 보면 select 수행 결과 해당 오브젝트의 코드가 list 자료형으로 반환되고있기 때문에 적절하게 변형하여 활용하면 된다.
[<span class="ball_645 lrg ball2">16</span>]
16
Sample
로또 당첨번호 조회 페이지는 url 에서 회차를 argument 로 입력받아 접근할 수 있으므로 url만 바꿔가며 1회차부터 836회차까지 데이터를 반복하여 수집할 수 있다.
아래 코드는 모든 회차의 당점 결과 페이지를 방문하여 당첨 번호, 보너스 번호, 등위별 당첨금액, 등위별 당첨 게임수를 dict 자료형으로 저장한다.
어떻게 이 데이터를 써야할 지 아직 미정인 관계로 pickle을 이용해 list로 묶어 일단 저장해놓는다.
#!/app/python/bin/python
# crawl_lotto.py
# dong1lkim
# 20181214
def ordinal(n):
if n == 1 : return '1st'
elif n == 2 : return '2nd'
elif n == 3 : return '3rd'
else : return str(n)+'th'
import requests
import re
from bs4 import BeautifulSoup
import json
result = [{"round": None,"win result": None}]
for i in range(1,837):
win_result = {"round":i}
url = "https://www.dhlottery.co.kr/gameResult.do?method=byWin&drwNo="+str(i)
html = requests.get(url).text
soup = BeautifulSoup(html,'html.parser')
win_nums = []
for j in range(1,7):
selector = '#article > div:nth-of-type(2) > div > div.win_result > div > div.num.win > p > span:nth-of-type('+str(j)+')'
win_nums.append(int(soup.select(selector)[0].text.strip()))
win_result.update({"win result":{"numbers":win_nums}})
selector = '#article > div:nth-of-type(2) > div > div.win_result > div > div.num.bonus > p > span'
bonus = int(soup.select(selector)[0].text.strip())
win_result.update({"win result":{"bonus":bonus}})
win = {}
for j in range(1,6):
selector = '#article > div:nth-of-type(2) > div > table > tbody > tr:nth-of-type('+str(j)+') > td:nth-of-type(2) > strong'
total = int(re.sub(r",|원","",soup.select(selector)[0].text.strip()))
selector = '#article > div:nth-of-type(2) > div > table > tbody > tr:nth-of-type('+str(j)+') > td:nth-of-type(3)'
numofwin = int(re.sub(r",","",soup.select(selector)[0].text.strip()))
win.update({ordinal(j):{"total amount":total,"number of winners":numofwin}})
win_result.update({"win result":{"numbers":win_nums,"bonus":bonus,"win":win}})
print(json.dumps(win_result,indent=4))
result.append(win_result)
import pickle
with open('lotto.bin','wb') as f:
pickle.dump(result,f)
f.close()
#with open('lotto.bin','rb') as f:
# data = pickle.load(f)
# f.close()


